Project Scope and ToDos
- Take a link and turn it into an oEmbed/Open Graph style share card
- Take a link and archive it in the most reliable way
- When the link is a tweet, display the tweet but also the whole tweet thread.
- When the link is a tweet, archive the tweets, and display them if the live ones are not available.
- Capture any embedded retweets in the thread. Capture their thread if one exists
- Capture any links in the Tweet
- Create the process as an abstract function that returns the data in a savable way
- Archive links on Archive.org and save the resulting archival links
- Create link IDs that can be used to cache related content
- Integrate it into the site to be able to make context pages here.
- Check if a link is still available at build time and rebuild the block with links to an archived link
Day 6
It looks like if I want to get any more complicated than the basics of the Wayback Machine's /save/ URL, I'll likely need to explore the Memento API structure. So, we'll start with the Memento intro.
Examining Memento
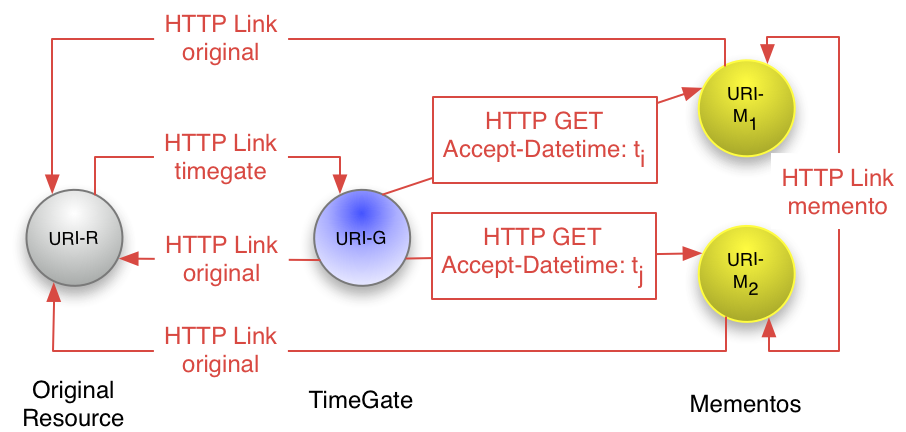
Ok the main points here are that there are three Memento entities joined over a link-based time map:
- TimeGate
- TimeMap
- Memento
It seems that whoever builds the site would be responsible for the first two entities, so I want to really (at least for now) drill down into the Mementos. There is a spec for Mementos as well and a useful slideshow. But most of this is looking at the access protocol, not the actual process of creating the archive.
Let's look for some guidance from the Archive Team projects. There are a few places that might be useful starts. There's grab-site and wpull.
I think the place to start is running a little test of grab-site locally. Let's try it out.
Adding Readability to the Link Object
I also wonder if it makes sense to have a less complex archive shipped in this initial package, like taking the already downloaded HTML document and processing it with Readability.
I'll start with npm install @mozilla/readability and incorporate it into building my link object.
Like I did with the other sources of metadata, I'll add it to the core object so people can do what they wish with it when they pull in this package. Let's make sure that this new property is properly covered with unit tests.
git commit -am "Add readability object to output"
Ok. I got that working!
Trying out grab-site
I want to switch back--now that I've installed it--to grab-site and see how it works.
Hmmm, it does not. It appears I have some missing libraries here. I'll have to run some system level updates. Let's see if that works.
It looks like the key was running softwareupdate --all --install --force and then sudo xcode-select --switch /Applications/Xcode.app/ on my OSX machine. Yup, that got it working!
Wow, when I archive a page with no additional actions it crawls way deep into every related page and link huh? I was thinking it might be possible to run this in a Github Action virtual machine. But if I even want to try that I'll have to think about ways to limit it. And on top of everything else, grab-site at least creates WARC files, which aren't ready to deploy to a static site that can then be browsed in a normal browser the way I would want to have this work. I'd either have to find different tools or some way to transform the WARC file into a browser accessible website. I'm sure there's a way, perhaps this ReplayWeb package or some other method, but I'll have to dig into it.
As I'm starting to examine grab-site and wpull and I'm wondering if building a Memento of a site is something that is going to be easy to do in Node. There are some utilities that it looks like have been adapted from Python into node that I can explore: warcio.js and node-warc. At least if I do go down that route it will be a major project. It looks like I can also look at ArchiveWeb as a possible tool to emulate or some related tools? It might make more sense to handle it in another way. It's still worth digging into, but I'm wondering if I need to put a more complex archiving process aside to work on some other components. Let's put a pin in it for now.
Ok, I think it's a good place to stop for tonight!